結束了 CV 子系列,接下來要來介紹完全不同於 supervised / unsupervised learning 的訓練方法 —— reinforcement learning(RL,強化學習)。
2013 年 Google DeepMind 團隊發表遊戲 Atari 基於 DL 和 RL 訓練出能打敗人類的 AI,也是 DL 與 RL 成功結合的先端。此後 deep RL 受到關注,在遊戲界和機器人界陸續有了新的斬獲,其中最舉世皆知的突破莫過於 2016 年同樣也是 DeepMind 團隊發表的圍棋 AI AlphaGo,以 4:1 戰勝當時世界上最厲害的圍棋高手李世石。這些成果也讓人非常期待 RL 未來能在其他應用領域帶來更多突破。
那就讓我們先從 RL 的基本架構看起,再帶到經典的 Atari AI 怎麼運用 DL 和 RL 做結合,來認識 RL 這個有趣的訓練方法。
之前介紹過的 task 大部分是 supervised / unsupervised learning,他們大都基於 data 做訓練,從大量資料中找尋特徵以利於預測。Reinforcement learning 則走另一條路,是一種藉由和環境大量互動汲取經驗,從錯誤中學習的方法。
Reinforcement learning 的目標是 decision making(決策)。任何任務只要能夠轉換成這個目標,就可以用 RL 來訓練,非常有彈性。從遊戲中下一個動作、圍棋下一手的落點、機器人的下個控制動作,到廣告投放、影片推薦等等,都是在做決策,也因此都能成為 RL 的客戶,但好不好訓練又是另一件事了。
這跟人類的學習模式很接近。舉例來說,今天你參與一個社交場合,發現坐著很被動等人聊天會根本沒人理你,那你下次參加可能會想主動找人搭話。下次主動找人搭話了,卻發現聊的東西根本不著邊際,你就會想說啊算了,下次默默吃餐點可能更好。結果後來又發現錯過認識很多人的機會,非常可惜,那你可能又決定以後還是要在社交場合偽裝自己一下。事實上你的任何決定並沒有對錯(有別於 supervised learning 有正確答案),每個人對每個決定感受到的價值也不同,這種根據價值調整決策模式尋找平衡點的過程,其實就是 reinforcement learning。
那麼這個跟環境互動汲取經驗的框架,具體來說怎麼 formulate 呢?
RL 是建立在 Markov decision process (MDP) 的架構之上來模擬決策過程以進行訓練的,大致長這樣:

—— RL 框架。
這個框架包含了以下要素:
舉例來說,你想要用 RL 訓練一台自駕車(agent),讓他在某個環境(environment)中學習自動駕駛。在每個時間點 t:
上面只是模擬決策過程中的要素。這個環境還需要定義 state 與 state 之間怎麼轉換,以及每次轉換的 reward:
不過 reward 的計算方法需要嚴謹一點。當你在 state s,只考慮當下能獲得的 reward 來選擇 action 的話,未免有點短視近利。如果剛好這一步能離終點直線距離最近,但會走進死路呢?那顯然現在走別條路更好。
因此考慮 action 時,也需要考慮未來所獲得的總 reward,而非只有當下立刻能獲得的 reward。除此之外,總 reward 的計算需要包含 discount factor 來讓當前 reward 比未來的 reward 更受重視。方法如下:
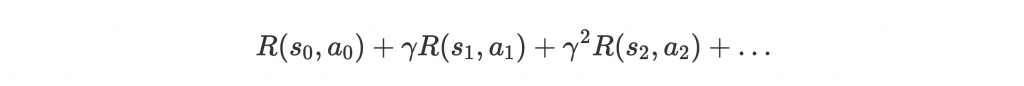
如此一來,太遙遠以後的 reward 比重較低,但如果他本身影響巨大,還是能左右現在的選擇。
環境中能影響 agent 學習的要素都準備好了,接著就是進入 agent 的腦袋。
Agent 最主要的目標就是學習到好的 policy ,也就是在 state s 選擇 action a,以完成任務:
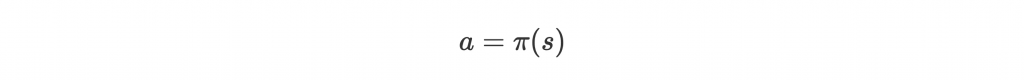
可以想像一個 agent 可以有無限種合法的 policy,但是我們想學的當然是最好的。不同 policy 可以用 value function 來評判好壞,有以下兩種形式:
第一種 value function 是 state-based,計算在 state s 時,根據 policy
走的話能獲得的 total expected reward:
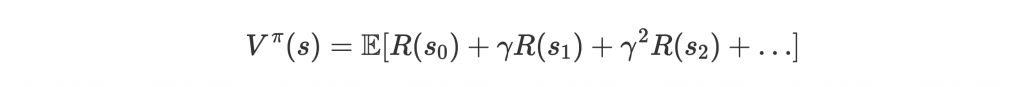
這個 value function 也可以用 Bellman equation 來表示,變成類似遞迴的計算:
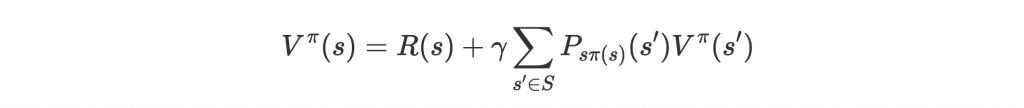
這樣的形式表示 value 是當下 reward R(s) 和所有進入 next state 的機率
乘上到達 next state 後的 discounted value
的總和。別忘了後面不過是期望值的計算方法。
畫了一個簡易圖,可以想像因為遞迴關係,我們會先從最後一個 timestep 計算 value(最後一步的 value 就是當下的 reward),一步步往前加總,直到遞迴到 timestep t 時,未來的 t+1 所有狀態都已經有了 value。Discount 以後加上現在獲得的 reward R(s),即可取得這個 state 的 value :

—— Value function as Bellman equation。
這樣的遞迴關係,方便我們用一個 model approximate ,訓練時就用同一個 model 預測
和
的值,並慢慢調整 model 讓
越來越 optimal、Bellman equation 能夠成立。
第二種 value function 稱為 Q-value function,計算在 state s 時,選擇 action a 後,再根據 policy 走的話能獲得的 total expected reward,同樣也能寫成 Bellman equation:
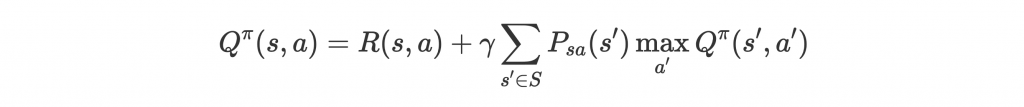
注意到這個式子和 其實是同樣的意思,因為
。
和
看起來頗像,但 Q-value 會更適合用找出最佳 policy。為什麼呢?
首先看到如果訓練出 optimal value function ,最佳 policy 會是:
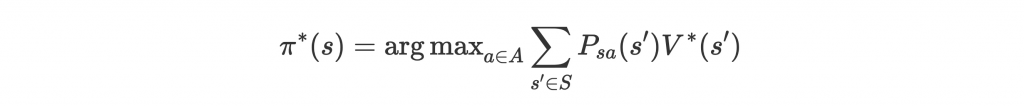
而訓練出 optimal Q-value function ,最佳 policy 會是:
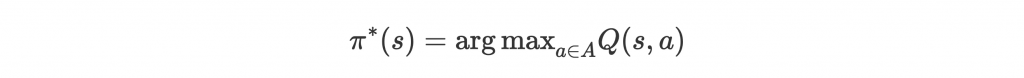
訓練 Q(s, a) 的話,policy 等於挑最大 Q-value 的 action 就好。但訓練 V(s),卻沒辦法很方便地轉換成我們要的 action,因為還需要 state transition probability。
從上面我們知道,要找出 policy,首先要先 approximate Q-value function。但是根據上面的數學,似乎需要知道環境的 state transition probability 才能計算 Q-value 並訓練 Q-value function。
這次來介紹簡單一點的訓練方法 Q-learning,不用 即可訓練,這種方法稱為 model-free learning。
這裡的 model 是指環境 model,不是 machine learning model。
Q-learning 大致流程如下:
其中最關鍵的是第四步:
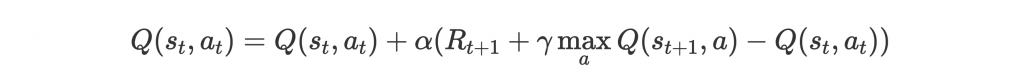
是 learning rate。這個方法其實很直覺,
是下個 state 實際上的 expected reward,但 model 一開始預測的是
,因此差距為
,update 時把這個差距藉由
慢慢補上。
說是實際上的 expected reward,但
中的 Q 在訓練中也只是估計值,主要是以環境真正返回的
為目標邁進。
(Mnih et al., 2013) Playing Atari with Deep Reinforcement Learning
(Mnih et al., 2015) Human-level control through deep reinforcement learning
介紹完 RL 的原理和 Q-learning 的學習方法,我們再藉由經典的 Atari paper 稍微統整一下剛剛的知識,還有 deep learning 如何和 Q-learning 結合。
Atari 是一套經典的電玩機遊戲,裡面包含的遊戲大多只需要簡單幾個控制:

—— Atari 遊戲畫面。
這篇 paper 主要目的是用 deep learning 結合 reinforcement learning 訓練這套遊戲的 AI。這在當時(2013 年)是一項創舉,開了 DL 結合 RL 的先河。
首先是 RL 框架的定義:
這可以說是 RL 最簡單的設定:現有的模擬器、簡單的控制動作、容易定義的 reward。新手想玩 RL 可以先從這類的任務下手。
Deep Q-network (DQN) 是 Q-learning 的一種,其中 Q-value function 用 neural network 來 approximate。
Model 是個簡單的 CNN model。Input 遊戲畫面作為 state s,經由 CNN 提取特徵,預測 個 Q(s, a)。Policy 會選擇使 Q(s, a) 最大的 a 當作控制動作。動作後由遊戲模擬器返回分數作為 reward,藉由 Q-learning update rule 更新 model 參數。

—— DQN model。
比較值得一提的是一些訓練技巧:
簡單秀一下 value function 的 visualization:

—— Game Breakout value function visualization。
上圖 Breakout 遊戲,左右控制下方的板子,讓球反彈打碎上方的方塊。y 軸 V 代表每個 state 的 total expected reward。右方 4 球彈到最上面後,可以預期會在上面反彈一陣子,能獲得很高的分數。

—— Game Pong Q-value function visualization。
上圖 Pong 遊戲,上下控制左右方塊,將球反彈到對面。y 軸 Q 代表每個 state 之下進行 action No-Op、Up、和 Down 的 total expected reward。中間 2、3 顯示右邊的方塊應該要往上走,才能接到球反彈到對面。
RL 的框架很彈性,可以套用在很多任務上進行訓練。但就算是 Atari 這麼基本的 task 都還需要很多額外的訓練技巧才能成功訓練,所以其實 RL 最困難的就是訓練的穩定性,還有訓練不成功時怎麼找出改進方法。
這次篇幅有點緊湊,一把從 RL 原理、value function、Q-learning,帶到 DQN 的 paper,內容偏學術一點。下一篇會藉由實作經典的 CartPole 問題帶大家更實際理解 RL。

